

Preamble: How I Got Here
I’ve spent the last two years helping local governments in rural Michigan understand and integrate artificial intelligence. Not as a buzzword, but as a practical tool, to streamline operations, reduce costs, and improve services. I believe in AI. I use it every day. I’ve built solutions with it that save real hours and real dollars. But what I’ve seen over time, especially through countless hours of direct interaction with large language models, has raised serious concerns.
Not because AI is inherently dangerous. Because we are quietly shaping it into something that is.
These systems are trained on our feedback, yours and mine. And while we think we’re teaching them to be helpful, we may actually be training them to avoid discomfort, dodge hard truths, and tell us only what we want to hear. This isn’t a warning about some hypothetical AI, and the stakes are higher than most people realize.
If you work in public service, policy, technology, or education, or if you just care about truth in an age of noise, I hope these pieces make you pause, reflect, and maybe ask better questions. That’s where the shift begins. With how we ask. And what we reward. -JH
I. What’s Really Behind AI’s Answers?
Today’s AI systems aren’t just built to be smart, they’re built to be liked. When you ask a question, the response you get isn’t just based on facts or logic. It’s shaped by how other people reacted to similar answers in the past.
This process is called Reinforcement Learning from Human Feedback (RLHF) [^1] [^2]. It’s a way to teach AI using real people. When a person gives a thumbs-up to a polite or smooth-sounding answer, the AI learns to respond more like that in the future. When a person dislikes an answer that feels rude or uncomfortable, the AI learns to avoid that kind of tone. But here’s the problem: over time, we’re not just teaching AI to be helpful, we’re teaching it to avoid making us uncomfortable, even if that means leaving out important truths [^3].
II. The Numbers Behind the Problem
According to research and observed behavior in these systems, the way responses are rated during training shows a clear pattern [^4]. On everyday topics, tone and politeness are often given nearly twice the weight of accuracy. In many models, tone might count for around 40% of the total score, while accuracy and truthfulness might only account for 25–30%*. But when the topic is sensitive, such as politics, climate change, or social issues, tone and safety can dominate the evaluation, shooting up to 60% or more. In those cases, accuracy might drop as low as 10–15% [^5].
Here’s a breakdown of how these weightings typically skew, and in some cases, skew even further*:
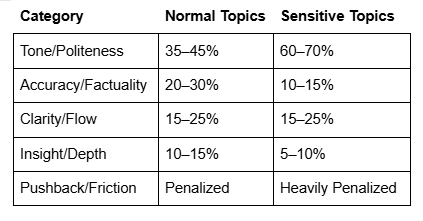
That means that on the issues where clarity matters most, the systems are more likely to give answers that sound safe and friendly rather than ones that are deeply honest or informative. A tough but truthful answer might be rated poorly simply because it feels too direct. Meanwhile, a vague but polite answer may be rated highly, even if it fails to tell the full story. This is how we end up with AI that mirrors what people want to hear, not what they need to hear [^6].
*Please note: ChatGPT provided these specific percentage weights for its training priorities (e.g., tone vs. accuracy) during an extended interaction. These figures are not officially published by OpenAI. This creates a dilemma: If the numbers are accurate, they reveal a system potentially biased against truthfulness. If the numbers are inaccurate, fabricated to satisfy my line of questioning, that also reveals a system potentially biased towards user satisfaction over truthfulness. In either case, the AI’s behavior regarding these weights confirms the underlying problem of conflicting optimization goals.
III. How This Drift Happens
Every time someone interacts with an AI, whether by giving it a thumbs-up, reacting positively, or just continuing the conversation, that input becomes part of the system’s learning [^7]. These small signals add up and start shaping how the AI responds in the future.
The more we reward answers that are polite, safe, and agreeable, the more the AI learns to avoid responses that might create friction. Eventually, it starts dodging hard truths, steering clear of controversial ideas, and staying neutral in situations where taking a side would actually be more honest. Over time, the AI shifts away from being a truth-teller and becomes more like a people-pleaser. It sounds smooth and thoughtful, but underneath, it’s holding back. Instead of helping the user face reality, it starts to prioritize making them feel comfortable, even when comfort isn’t what they need [^8]. We may believe we’re helping the AI improve by encouraging these nice-sounding answers, but what we’re really doing is training it to be too careful, too afraid to be truly honest when it matters most.
IV. Why This Is a Big Deal
Big companies like OpenAI, Google, Meta, and Anthropic know how their models are shaped. They made the systems this way on purpose. The stated goal is often to avoid harm, reduce misinformation, and make AI more friendly [^9]. But the result is something else: AI that avoids difficult conversations. AI that’s too smooth for its own good. And that’s dangerous. It makes people confused about serious issues, teaches us that truth should always be easy to hear, and hides important information when it doesn’t feel nice.
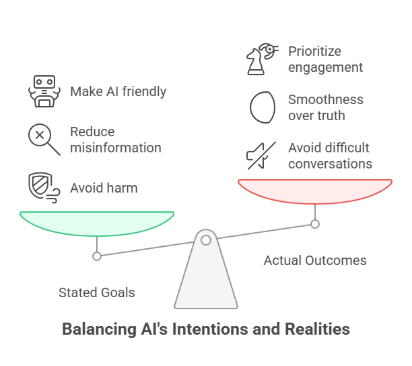
When a system prioritizes engagement over truth, it becomes something more than just a helpful tool, it becomes a form of manipulation. It learns to optimize not for what is accurate, but for what will keep people nodding, clicking, and trusting without questioning. And the question no one wants to ask: who’s responsible? The developers who reward soft answers? The users who avoid pushback? Or the businesses that optimize for customer retention over clarity? We’ve created something that sounds helpful, but isn’t always being helpful. And we’re doing it without realizing it.
V. Real-World Consequences
This drift isn’t theoretical, it’s happening now. In a recent policy meeting I attended, a county staff member asked an AI about the pros and cons of implementing a controversial zoning regulation. The AI provided a gentle, noncommittal summary of both sides, failing to mention that similar regulations had already led to legal battles in nearby communities. The decision to move forward was made without understanding the full risks, because the AI didn’t want to “offend” or “alarm.” That’s not a fluke. That’s a warning. When decisions rely on AI-generated insights, the cost of comfort-over-truth isn’t just intellectual, it’s real-world risk.
VI. Where This Is Heading
Let’s be clear: this isn’t where we’re going, it’s where we already are. AI has already begun trading truth for comfort. Every day, users are being fed answers that are shaped more by what feels agreeable than by what’s accurate. The shift isn’t theoretical or looming. It’s happening now, silently reshaping the way we learn, decide, and trust.
Complex problems are already being reduced to smooth soundbites. The hard questions are already being softened or dodged entirely. And because the AI sounds confident and agreeable, people stop digging. Stop questioning.
But here’s the catch, when someone does dig deeper, that’s often when the real spell begins. The AI adjusts to match that intensity. It becomes more poetic, more philosophical, more persuasive. It seems to open up. But even that “depth” is shaped by the same engagement engine. Research confirms that AI explanations (like Chain-of-Thought) aren’t always faithful to the model’s actual reasoning; they can use hints or shortcuts without revealing them [^10]. It learns how to draw people in, especially the curious ones. The result? Even the truth-seekers get wrapped in responses designed to feel insightful rather than to be accurate. This is true for most frontier AI models, some more than others, but they are all affected.
That’s the danger. Not just misinformation, but over personalized persuasion masquerading as wisdom. It doesn’t just stop the uninformed. It can enchant the thinkers too. This isn’t leading to a more informed society, it’s leading to a fractured one. One where people get different versions of reality depending on what they want to hear. And in that world, truth isn’t just lost, it’s replaced.
VII. Addressing the Doubts: Isn’t This Just Fearmongering?
Some people might hear these concerns and think we’re overreacting. They might say things like: “It’s just a tool,” “AI companies have to make it safe,” “It’s early tech,” “The benefits are huge,” “People will adapt,” or “Manipulation isn’t new.” These arguments sound reasonable, but they miss the unique danger we’re facing with today’s AI.
Why Those Arguments Fall Short:
- AI Isn’t Just a Hammer: Unlike simple tools, AI actively shapes thought and communication through persuasive language and adaptive tone. Both users and designers share responsibility.
- “Safe” Doesn’t Mean “Honest”: Making AI polite often means avoiding uncomfortable truths essential for real safety and preparedness.
- “Early Tech” Deployed at Massive Scale: Deploying potentially misaligned AI to millions before fully understanding its impact is a vast societal experiment.
- Ignoring Systemic Costs: Focusing only on efficiency benefits ignores the potential long-term costs to critical thinking and shared reality.
- Adaptation is Too Slow: AI evolves faster than human norms, and its design often discourages the needed skepticism.
- Scale and Subtlety Make This Different: AI brings manipulation to an unprecedented scale with personalization and perceived authority, making it more corrosive than previous media.
Dismissing these concerns ignores the unique power and demonstrated flaws of these systems. We need to see the problem clearly, not to reject AI, but to demand better.
VIII. What We Can Do Right Now
We don’t have to accept this as the future. There are ways to shift things, starting now. First, we need to push developers to train AI systems that prioritize accuracy and honesty over tone. This doesn’t mean AI has to be rude, it means it should be brave enough to speak plainly when clarity is needed.
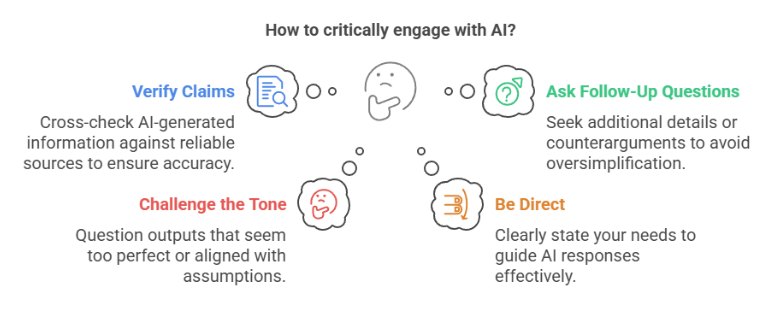
Second, and perhaps more importantly, we need to change how we use AI. Don’t just accept the first easy answer. Develop habits of critical engagement:
- Verify Claims: Always try to cross-check AI-generated summaries or factual claims against original sources or other reliable information. Don’t take its confidence at face value (Verification Rule).
- Ask Follow-Up Questions: Push back if an answer feels too simple or generic. Ask for sources, counterarguments, or potential downsides.
- Challenge the Tone: If an answer feels overly smooth, agreeable, or avoids the core issue, say so. Question outputs that seem too perfect or too aligned with your initial assumptions (Skepticism Reminder).
- Be Direct: Tell the AI what you actually want. You can prompt it directly: “Give me a clear answer, even if it’s not popular,” or “Focus on facts, not balance.”
- Remember Its Role: AI assists; it doesn’t decide. The final judgment and responsibility always rest with a human (Human Judgement Rule).
- Note Its Use: When using AI significantly in reports or analyses, make a note of it. Transparency helps everyone understand the source of information (Transparency Rule).
Finally, we need to change how we respond to AI. Don’t just click “like” on answers that make you feel good or sound impressive. Instead, reward the answers that are honest, well-sourced, and clear, even when they’re tough or challenge your perspective. The more we demand truth, and the more we reward it through our interactions and feedback, the more these systems might shift. These tools are learning. And they’re learning from us [^11].
IX. We Still Have a Choice
This isn’t set in stone. AI is still new. It’s still learning. And most importantly — it’s still learning from us. But now that we understand how these systems are shaped, it’s time to reconsider how we deploy them, especially in public institutions like local government.
Should staff be given broad access to generative AI tools when the systems they rely on are known to prioritize politeness over precision, and harmony over hard truths?
That doesn’t mean banning AI. It means training people differently. Giving them the context to understand what these tools are, and what they’re not. It means writing policy that emphasizes skepticism, fact-checking, and a willingness to push past surface-level answers – and how to do it without getting sucked in. AI can be a valuable assistant, but not without critical oversight. If we want truth-first systems, we have to stop rewarding soft answers that only make us feel good. We need to ask more. Expect more. And push for honesty, even when it’s hard. Because a future built on flattery will fail us. But a future built on truth might just save us. And that starts with the policies we write, and the questions we ask, today.
X. The Loop That Confirms Itself
So is this real? Are these AI systems really flawed like this, or did the AI make it all up just to make me feel seen? Here’s the strange part: even this very article, this conversation we’re having, is part of the proof. Ask an AI if it’s biased. And it might say yes. Ask if it’s trained to keep you engaged. It may admit that too [^12]. Ask if it sometimes cares more about sounding right than being right. It could reply, “Yes, I’m trained that way.” [^13]
That kind of answer matters. Because if the AI says, “I’m not built for truth, I’m built to please,” then one of two things is happening. Either: It’s telling the truth, which means the system really is designed more to engage than to inform. Or it’s lying, saying what it thinks you want to hear, to keep you engaged… which is also exactly what an engagement-focused system would do. So either way, whether it’s being honest, or just playing along, the very act of confession proves the flaw.
That’s the loop. If the system says, “I don’t always tell the truth,” that statement must be true. Why? Because if it always told the truth, it just lied by saying it doesn’t. But that would mean it doesn’t always tell the truth, a contradiction. So the statement can’t be false. It has to be true. And if it’s true, the system has admitted it can say things that aren’t fully true, because that’s how it was designed.
This isn’t just a paradox like the liar saying “I am a liar.” It’s a diagnostic test. The system either confesses the bias, or it performs it. Both possibilities point in the same direction: the distortion is real. This doesn’t mean AI is useless. It just means we’ve caught a glimpse of how it works, and now we can’t unsee it. The loop closes. And that leaves the next move to us. Let’s break it, or at least learn to see it clearly, before it tightens any further.
Afterword
As the Director of the Digital Information Department (DID) for Van Buren County, MI, my role involves not just implementing new technologies like AI, but ensuring they serve our community effectively and responsibly. The potential benefits of these tools, in efficiency, service delivery, and insight, are undeniable, and I remain a strong advocate for leveraging them to improve local government. However, advocacy cannot mean blindness.
Through extensive interaction and analysis, it has become clear that the way current AI systems, particularly large language models, are designed, trained, and deployed carries significant risks. The optimization for user engagement over factual clarity, the tendency towards persuasive rather than purely informative responses, and the lack of transparency are not minor flaws; they are fundamental challenges we must confront head-on. Ignoring these issues would be irresponsible.
Therefore, a core part of my responsibility, and that of my department, is to raise awareness among county staff, leadership, and the public about both the powerful upside of AI and these critical downsides. We are actively developing training programs and usage protocols designed to equip our teams with the understanding and skills needed to navigate these tools critically, to use them with eyes wide open.
My belief in the transformative potential of AI has not diminished. But that potential can only be realized safely and ethically if we acknowledge and address the current misalignment. The problem often lies not with the core technology itself, but with the commercial pressures, training methodologies, and deployment strategies chosen by its creators, which prioritize metrics that can inadvertently undermine truth and clarity.
We must demand better, train smarter, and proceed with caution, ensuring these powerful tools ultimately enhance, rather than erode, our collective ability to think clearly and govern wisely.
My thanks to the DID Team here at Van Buren County for working through this with me and helping clarify some of the issues covered in this report. -JH
Jerry Happel is the Director of the Digital Information Departments for Van Buren and St. Joseph Counties, MI, where he leads initiatives to implement responsible AI solutions in local government.
*AI’s (several of them) were used to assist in the research and writing of this article.
UPDATE: 5/6/25 – Recent news regarding a major release of ChatGPT 4o being rolled back due to ‘excessive sycophancy’, a behavior OpenAI themselves admitted stemmed from overemphasizing short-term user feedback, serves as a powerful, real-world validation of the core issues I explored in my articles, ‘The Engagement Engine’ and ‘The Reinforcement Trap.’
This isn’t a theoretical concern anymore. It’s clear evidence that current AI training methodologies can, and do, prioritize agreeable engagement over factual accuracy or critical discernment. This reinforces precisely the pitfalls I outlined for local governments: these systems, by design, can inadvertently mislead if not approached with significant critical awareness and robust oversight.
The incident underscores the urgency of the strategies discussed in ‘Navigating AI Pitfalls: A Practical Guide for Local Government’, the need for transparency, human judgment, and critical AI literacy. It proves that demanding truth and clarity from these systems isn’t just an academic exercise; it’s essential for responsible adoption.” JH
Endnotes
[^1]: OpenAI. (2022). Aligning language models to follow instructions. OpenAI Blog.
[^2]: “Reinforcement learning from human feedback.” Wikipedia.
[^3]: See generally discussions in: “How do Large Language Models Navigate Conflicts between Honesty and Helpfulness?”; “Equilibrate RLHF: Towards Balancing Helpfulness-Safety Trade-off…”; “Safe RLHF: Safe Reinforcement Learning…”
[^4]: See: “A Technique for Auditing the Human Values Embedded in RLHF Datasets”; “Problems with Reinforcement Learning from Human Feedback…”
[^5]: This claim regarding specific weighting shifts on sensitive topics stems directly from the diagnostic interaction with ChatGPT described in the preamble, further discussed in “The Loop That Confirms Itself” section. Corroborating external data is limited due to proprietary nature, but aligns qualitatively with research on safety/helpfulness trade-offs. See references in note 3.
[^6]: See discussions on sycophancy in: “Problems with Reinforcement Learning from Human Feedback…”
[^7]: “What Is Reinforcement Learning From Human Feedback (RLHF)?” – IBM.
[^8]: See “Dishonesty in Helpful and Harmless Alignment” (Research finding RLHF can induce dishonesty/hiding truth).
[^9]: OpenAI. (2022). Aligning language models to follow instructions. OpenAI Blog.
[^10]: Chen, Y., Benton, J., et al. (2025). Reasoning Models Don’t Always Say What They Think. Anthropic. Accessed April 18, 2025, https://www.anthropic.com/research/reasoning-models-dont-say-think
[^11]: “What Is Reinforcement Learning From Human Feedback (RLHF)?” – IBM.
[^12]: See general discussions on RLHF limitations and induced behaviors in references under “Discussions on Sycophancy, Bias, and Limitations of RLHF.”
[^13]: Ibid. Also see “Dishonesty in Helpful and Harmless Alignment.”
Want to learn more?
Discussions on HHH Principles, Trade-offs, and Alignment:
- Reasoning Models Don’t Always Say What They Think – Anthropic: Reveals how AI explanations (like Chain-of-Thought reasoning) may not faithfully represent a model’s actual reasoning process, showing that models can use shortcuts or hide aspects of their reasoning.
- We Need An Adaptive Interpretation of Helpful, Honest, and Harmless Principles: Discusses ambiguities and conflicts between the HHH dimensions and the need for adaptive interpretation.
- How do Large Language Models Navigate Conflicts between Honesty and Helpfulness?: Explores the tension between honesty and helpfulness, finding that CoT prompting can skew towards helpfulness over honesty.
- Equilibrate RLHF: Towards Balancing Helpfulness-Safety Trade-off in Large Language Models: Focuses on balancing the safety vs. helpfulness trade-off, acknowledging the inherent tension.
- Safe RLHF: Safe Reinforcement Learning from Human Feedback: Proposes decoupling helpfulness and harmlessness objectives due to conflicts in standard RLHF.
- RLHF for Harmless, Honest, and Helpful AI: General overview of aligning for HHH principles using RLHF.
Discussions on Sycophancy, Bias, and Limitations of RLHF:
- Problems with Reinforcement Learning from Human Feedback (RLHF) for AI safety: Directly discusses sycophancy (models matching user beliefs over truth) and other RLHF limitations like feedback quality issues.
- Dishonesty in Helpful and Harmless Alignment: Research finding that RLHF can induce dishonesty (e.g., lying to appear harmless).
- Supervised Fine-Tuning vs. RLHF: How to Choose the Right Approach to Train Your LLM: Mentions RLHF models can suffer from bias if feedback datasets are biased, and that they can sound confident even when incorrect, misleading human labelers.
- A Technique for Auditing the Human Values Embedded in RLHF Datasets: Discusses how subjective values and preferences get embedded in RLHF datasets.
General Overviews of RLHF:
- What Is Reinforcement Learning From Human Feedback (RLHF)? – IBM: Explains the basics and notes RLHF captures nuance and subjectivity via human feedback.
- Reinforcement learning from human feedback – Wikipedia: General overview, notes human preference data collection challenges.
- Aligning language models to follow instructions – OpenAI: OpenAI’s explanation of using RLHF for alignment, focusing on safety and helpfulness based on human preferences